Support Vector Regression
Support Vector Regression (SVR) is a machine learning model that makes use of SVM (Support Vector Machine) concept to make continuous valued predictions by estimating functions that are dependent on a given set of data. It is a more advanced version of simple linear regression. In simpler terms, SVR delivers a linear regression that is influenced by the chosen margin, especially when dealing with outliers.
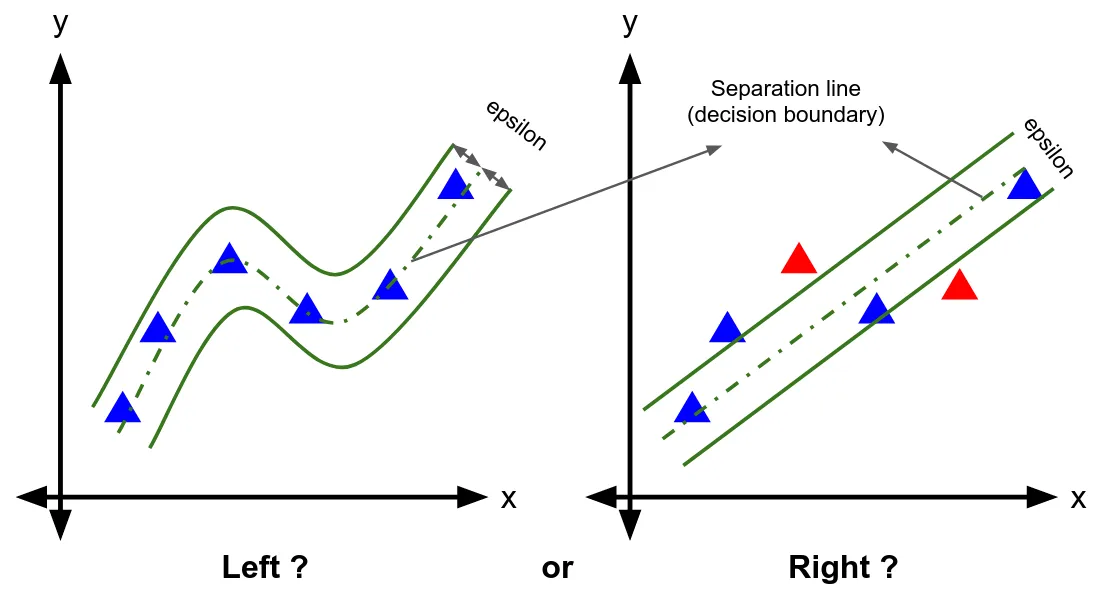
How Does Support Vector Regression Work?
Just like SVM, SVR utilizes the concept of a decision plane that defines decision boundaries. Here, a decision boundary is used to estimate the function that best fits the distribution. Anything within the decision boundary is the non-admissible margin.
SVR has the capacity to restrict the error of each point in the training set within a certain threshold. Unlike other regression models that reduce the error rate, SVR offers a fitting accuracy specified within an established error boundary.
Creating Support Vector Regression Models in Python:
# Importing Libraries
from sklearn.svm import SVR
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Preprocessing
data = pd.read_csv('data.csv')
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# Feature Scaling
scaler = StandardScaler()
X = scaler.fit_transform(X)
y = scaler.fit_transform(y.reshape(len(y), 1))
# Splitting the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Training the model
svr = SVR(kernel='rbf')
svr.fit(X_train, y_train)
# Predicting values
predictions = svr.predict(X_test)
Advantages of Support Vector Regression:
-
Mentioned regression method can be used to resolve both linear as well as non-linear issues. It uses Kernel trick which does a good job at non-linear regression tasks.
-
SVR is equipped with a defined regularization parameter, which makes the user think about avoiding over-fitting. It proposes stiffness on selecting hyperplane by regulating the parameters of the python machine learning model.
-
SVR gives a unique prediction irrespective of the size of the input space and it doesn’t get affected by outliers.
Disadvantages of Support Vector Regression:
-
SVR is not suitable for large datasets because the time complexity of one iteration in SVR is between O(n²) to O(n³). So, it can’t be used for larger datasets.
-
They have high training time and it’s quite complex and difficult to understand and interpret.
-
Choosing an appropriate kernel function is not always easy and can be tricky. The results are also hard to interpret.
-
Tuning SVR hyperparameters is not easy. Incorrect choice of kernel and hyperparameters may lead to overfitting or underfitting.
Scenarios to Use SVR:
-
In cases where predictions that are not observed in the training set are required to be made.
-
When working with datasets that have more features. In this case, SVR can be a feasible choice as it can efficiently handle multi-dimensional space.
-
SVR has been used in applications in many domains, including text and hypertext categorization, image analysis, bioinformatics and medical applications.
-
Especially useful for predicting values that fall within a specified range.
-
In cases where the removal of noise from the dataset priority, as SVR has an excellent capability of noise handling.
In conclusion, it is a powerful regression technique and is much more customizable than other methods. When we are working with data that’s fit is not linear then SVR can be a good technique to go within a margin of tolerance.