Gradient Boosting & AdaBoost Regression
Gradient Boosting and AdaBoost are popular ensemble methods used in machine learning. They utilise multiple learning algorithms to obtain better predictive performance that could not be obtained from any of the constituent learning algorithms alone.
Let's discuss these two methods and how they apply to regression tasks:
Gradient Boosting Regression
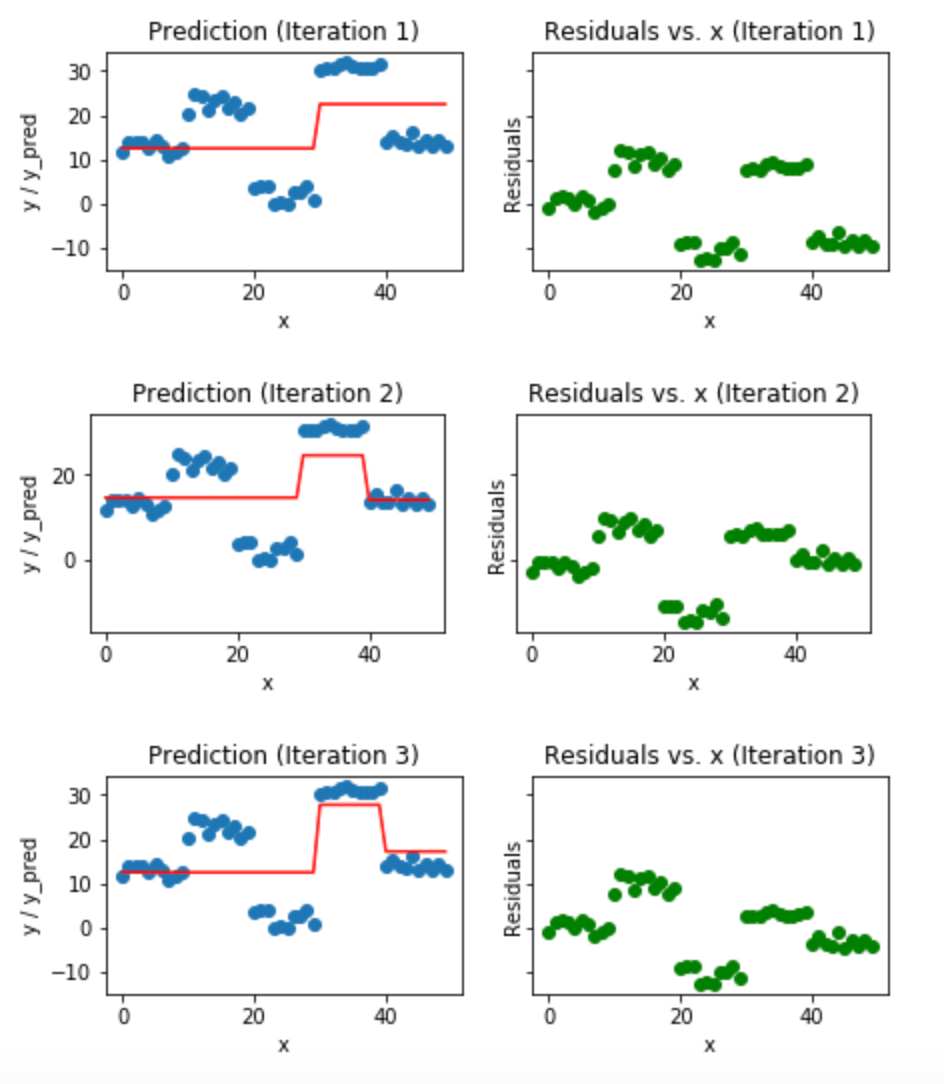
Gradient Boosting is a machine learning algorithm based on decision freeze that develops multiple weak learners (typically decision trees), and then combines them to make a single strong learner.
Gradient Boosting algorithm works on the principle of boosting weak learners. Here, the losses of one tree are recovered by the next tree. It makes new learners focus more on the instances that previous learners classified incorrectly.
Code sample using Python's scikit-learn library:
from sklearn.ensemble import GradientBoostingRegressor
regressor = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
regressor.fit(X_train, y_train)
Advantages
-
It's very flexible - it can optimize on different loss functions and provides several hyperparameter tuning options that make the function fit very flexible.
-
No data pre-processing required - often produces great results without scaling or handling outliers.
Disadvantages
-
GBMs are more sensitive to overfitting if the data is noisy.
-
Training generally takes longer because of the fact that trees are built sequentially.
-
It's harder to tune than other models due to complexity of the hyperparameters.
Use Cases
-
Anomaly detection in supervised learning settings where the data is often highly unbalanced.
-
Regression and classification problems.
AdaBoost Regression
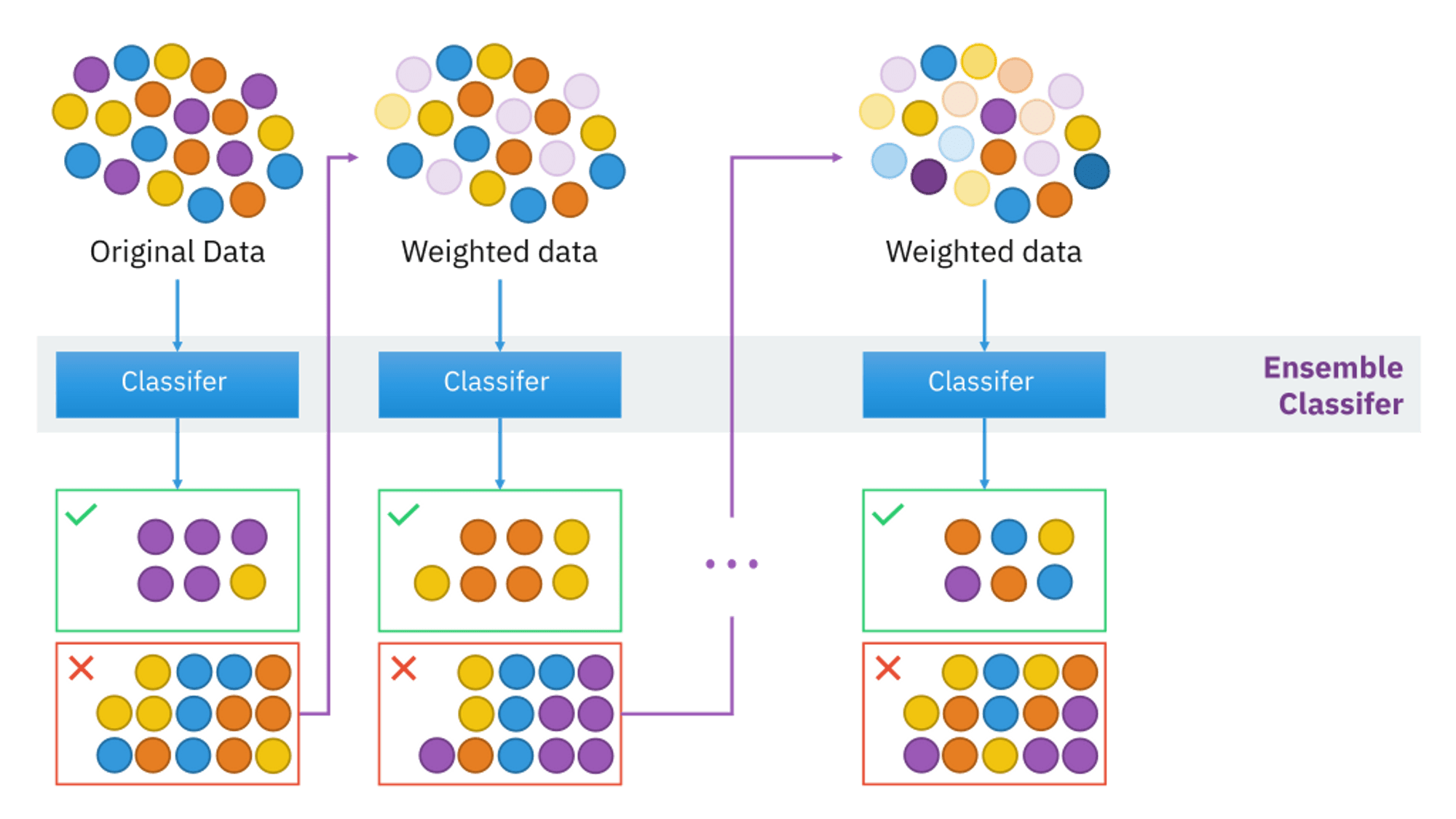
AdaBoost, short for Adaptive Boosting, is a statistical classification meta-algorithm. It can be used in conjunction with many other types of learning algorithms to improve their performance on regression tasks. It focuses on classification problems and aims to convert a set of weak classifiers into a strong one.
Code sample using Python's scikit-learn library:
from sklearn.ensemble import AdaBoostRegressor
regressor = AdaBoostRegressor(random_state=0, n_estimators=100)
regressor.fit(X_train, y_train)
Advantages
-
AdaBoost is easy to implement. It iteratively corrects the mistakes of the weak classifier and improves accuracy by combining weak learners.
-
The user only needs to choose: (1) which weak classifier might work best to solve their given classification problem, and (2) the number of boosting rounds that should be used during the training phase.
Disadvantages
-
AdaBoost can be sensitive to noisy data and outliers.
-
The performance of AdaBoost depends on the data and the weak learner. Consequently, there's a need for tweaking and testing to make it work perfectly.
Use Cases
-
Face detection as a binary categorization problem of face vs non-face.
-
Predicting customer churn and classifying the types of topics customers are talking/calling about.
Comparing Gradient Boosting and AdaBoost
While both Gradient Boosting and AdaBoost work on the principle of boosting weak learners, there are some differences in their implementation of this principle.
-
Gradient Boosting improves the model using the gradient descent algorithm, which adjusts the weight of an instance based on the residual error. AdaBoost, on the other hand, adjusts the weight based on the sum of the weighted error.
-
In AdaBoost, the weak learner's decision stump makes decisions based on single features, while in Gradient Boosting, decision trees can be used, which make decisions based on multiple features.
Overall, both are powerful algorithms that have proven to be very useful in machine learning tasks, more specifically in regression problems.