Gradient Boosting Classifier
Gradient Boosting Classifier is a set of machine learning algorithms that's primarily used for handling regression and classification problems in a supervised learning setting. It belongs to the class of boosting ensemble methods, where new models are added to correct the errors made by the existing models.
The term 'Gradient Boosting' originates from the fact that the algorithm uses gradient descent to minimize errors.
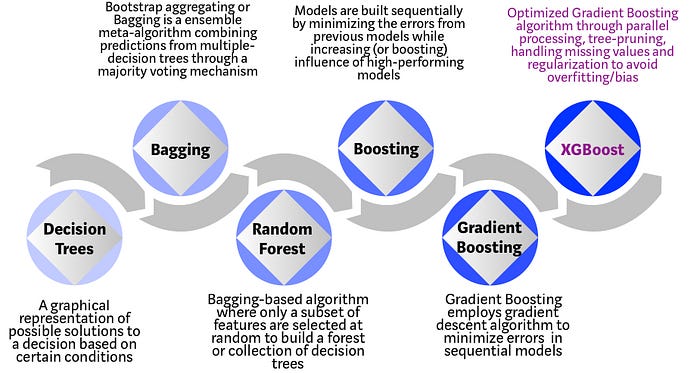
How it works
Here's a step-by-step breakdown of how Gradient Boosting Classifier works:
- A model is built on a subset of data.
- This model is used to make predictions on the whole dataset.
- Errors are then calculated by comparing the predictions and actual values.
- A new model is created that predicts these errors.
- This process is repeated until the algorithm can't minimize the error anymore.
Gradient Boosting involves three elements:
-
A Loss function: The loss function is a measure showing how good our model’s predictions are. We want a loss function that can be optimized better. So it should be differentiable.
-
A weak learner: For boosting problem, decision trees are used as a weak learner. They are used because of their interpretability, simplicity and computational effectiveness
-
An Additive model: Gradient boosting involves the creation of an ensemble of sequential weak learners, each correcting the predecessor's mistakes.
from sklearn.ensemble import GradientBoostingClassifier
#Creting an instance of GradientBoosting classifier
gbc = GradientBoostingClassifier(random_state=0)
#Training the classifier
gbc.fit(X_train, y_train)
#Making predictions
y_pred = gbc.predict(X_test)
Advantages of Gradient Boosting Classifier
- Great predictive power: Gradient Boosting algorithms are known for their impressive predictive capacities.
- Flexibility: They can be used in both regression and classification problems, and it works well with various types of data.
- Handle missing data: Gradient Boosting can handle missing data without the need for imputation.
- Feature Importance: GBC use decision trees where feature importance is a measurable strategic benefit.
Disadvantages of Gradient Boosting Classifier
- Overfitting: If the data sample is too small, Gradient Boosting algorithms tend to overfit.
- Requires careful tuning: It requires careful tuning of different hyperparameters, which can sometimes be computationally expensive.
- Long training period: Gradient Boosting might take longer to train as trees are built sequentially.
When to use Gradient Boosting Classifier
Gradient Boosting can be used effectively for a variety of machine learning tasks like classification, regression, ranking etc. It works extremely well on structured data, where there is a clear definition of entities - customers, products, user, etc.
On an industry level, it can be used for credit scoring, churn prediction, anomaly detection in cyber security, predicting machine faults in predictive maintenance etc.
In scenarios where accuracy is more important than interpretability, and where computational time isn’t a focus point, it shines out as a good choice.
Gradient Boosting Classifier is often your best bet if you prioritize predictive power over model interpretability. It performs well in situations where the dataset has multiple complex relationships because it combines multiple 'weak learners' to create one strong rule.
Furthermore, if you are working with a combination of categorical and numerical features, or just numerical but expect non-linear relationship, you can use Gradient Boosting Classifier. It also perfectly fits in scenarios where you're less bothered about model interpretability and more focused on creating accurate predictions.
Overall, Gradient Boosting Classifier is a powerful algorithm that performs excellently in a wide range of tasks. However, depending on your specific needs and the constraints of your project, other algorithms might be a better fit. Therefore, always consider the strengths and weaknesses of each algorithm and strive to understand the needs of your project before making a decision.